
")


It is a common misconception that FAIR data must always be completely open and that all open data are inherently FAIR. However, this is not the case. Let us explore the definitions of both concepts and clarify the differences between them.
What Is Open Data?
Open Data refers to data that can be freely accessed, reused, and redistributed by anyone. This concept is grounded in the principle of universal access, meaning that data should be available to all without the need for special permissions or payments. However, it is also important to note that the reuse and redistribution of open data are often regulated by licenses, such as Creative Commons, to ensure proper usage and attribution.
What Is FAIR Data?
FAIR data refers to data that follows the FAIR principles: findable, accessible, interoperable, and reusable. These principles were formalized in 2016 to guide better data management and stewardship, particularly in the context of digital research outputs:
- Findable: Data should have rich metadata and unique identifiers, making it easy for researchers and tools to locate it.
- Accessible: Data and metadata should be retrievable through standardized protocols, possibly with authentication when necessary.
- Interoperable: Data should use formats, vocabularies, and standards that allow for integration with other datasets.
- Reusable: Data should have clear usage licenses and detailed provenance to enable validation and reuse.
Importantly, the FAIR principles do not require data to be open, as we will see in the next section, but instead focus on how data should be organized and described to maximize its discoverability and reuse by both humans and machines.
Notice that FAIR is a spectrum, not a binary state! Data can be more or less FAIR depending on the quality of metadata, the use of standards, and other factors.
The Difference Between FAIR Data and Open data
FAIR is not equal to open. The “A” in FAIR refers to “accessible under well-defined conditions”, which means that data do not necessarily need to be open to everyone. There are circumstances where openness could pose risks, such as with confidential or personal data. In essence, data should always be FAIR, but they are not required to be open in all cases.
However, it is important to note that data or data infrastructures should not use the FAIR principles as a justification for restricting openness when it is appropriate and necessary to share the data!
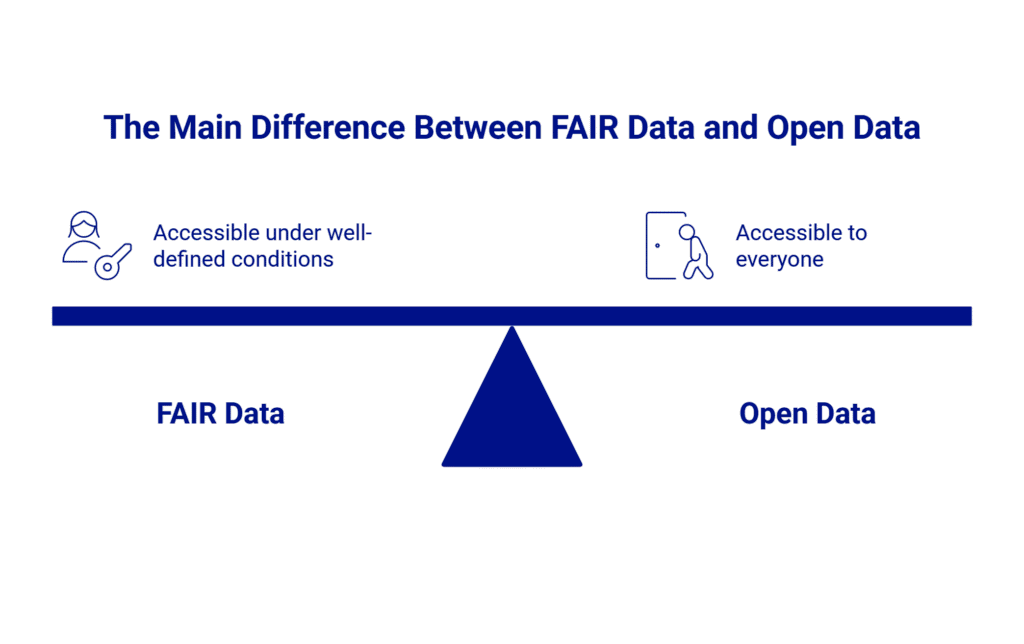
Beyond accessibility conditions, another key distinction lies in the focus of each concept: FAIR is primarily concerned with how data are structured, described, and managed to enable effective discovery, interoperability, and reuse, whereas open data is primarily concerned with legal permissions and the removal of access barriers. Data can be openly available online yet lack sufficient metadata, standardized formats, or clear provenance, making them difficult to interpret or reuse in practice. Ideally, data should be both FAIR and open whenever possible, but the two concepts address different dimensions of responsible data sharing.
New Horizons in Open and FAIR Data
As we approach the 10th anniversary of the FAIR data concept in 2026, it is essential to consider today’s evolving data requirements. With the rapid rise of AI, data needs extend far beyond just being FAIR. Some suggestions to extend the FAIR principles include:
The extension of the FAIR principles to FAIR-R (where the “R” stands for readiness) has been proposed to address the specific needs of AI systems. In this context, data readiness for AI refers to the process of preparing and ensuring the quality, accessibility, and suitability of datasets before they can be used in AI applications.
Or the proposal of adding the dimension of “understanding,”, sugested in a recent article in the Scholarly Kitchen. This proposal emphasizes that data should not only be accessible and reusable, but also comprehensible and interpretable within specific contexts.
As we move forward, the future of open and FAIR data lies in their ongoing refinement to meet the ever-changing demands of technology, ethics, and research, ensuring that data remains not just accessible and reusable, but also ready for the challenges of modern AI and beyond.